/ АНАЛИЗ АРХИТЕКТУРА ДАННЫЕ: + ДАННЫЕ + Информация - SQL intro ` Ресурсы ` Настройки MySQL ` Создание таблицы ` Извлечение данных ` Добавление данных в таблицу ` Изменение данных в таблице ` Удаление данных из таблицы ` Изменение таблицы и столбцов ` Windows. SQLCMD. ` Разное + MongoDB intro DevOps Gaming Библиотека ПРОЦЕССЫ ТЕСТИРОВАНИЕ
sudo service mysqld stop
sudo killall -9 mysqld
sudo /etc/init.d/mysql restart
Если в логах ошибка
> InnoDB: Check that you do not already have another mysqld process
> InnoDB: using the same InnoDB data or log files.
sudo cp -a /var/lib/mysql/ibdata1.bak /var/lib/mysql/ibdata1
|
СОЗДАНИЕ ТАБЛИЦЫ, где column_names — имя столбца; data_type — тип данных size — максимальная длина значения Использование PRIMARY KEY и ограничений (constraint) — опционально О типах и ограничениях — ниже. |
CREATE TABLE table_name ( column_name1 data_type(size) [contstraint], column_name2 data_type(size) [contstraint], column_name3 data_type(size) [contstraint], .... columnN data_type(size) [contstraint], PRIMARY KEY(columnN) ); |
|
Пример. Создаем таблицу с 4 столбцами: логин (не более 20 символов) обязательное, пароль (не более 15 символов) обязательное, пол (мужской или женский) не обязательное, дата рождения (тип дата) необязательное. |
CREATE TABLE users ( id int NOT NULL AUTO_INCREMENT, login varchar(20), password varchar(15), sex enum('man', 'woman') NULL, date_birth date NULL, PRIMARY KEY(id) ); |
Другие ограничители:
UNIQUE — не позволяет вставлять дублирующееся значение в столбец.
CHECK — проверяет валидность/невалидность значения по логическому выражению
DEFAULT — в случае когда при вставке новой записи не задаётся значения для этого столбца, то будет вставлено значение ПО-УМОЛЧАНИЮ
AUTO_INCREMENT — генерирует уникальный номер для вставляемой строки. По-умолчанию, изначальное значение для автоинкремента равно 1, для каждой последующей записи будет добавляться ещё единица.
Пример: UserID int NOT NULL AUTO_INCREMENT,
PRIMARY KEY (UserID)
Некоторые типы данных
Числовые
INT — целочисленное, может быть со знаком;
FLOAT(M,D) — вещественное, где (опционально) M — общее количество символов, а D — количество символов после запятой
DOUBLE(M,D) — вещественное с большим диапазоном, где (опционально) M — общее количество символов, а D — количество символов после запятой
Дата и время
DATE — дата в формате ГГГГ-ММ-ДД
DATETIME — дата и время в комбинации ГГГГ-ММ-ДД ЧЧ:ММ:СС
TIMESTAMP — timestamp, отсчитывающийся от January 1, 1970
TIME — хранит время в формате ЧЧ:ММ:СС
Строковые
CHAR(M) — позволяет хранить строку фиксированной длины М
VARCHAR(M) — позволяет хранить строку переменной длины
TEXT — позволяет хранить большие объемы текста. Используется для хранения именно текста.
BLOB — "Binary Large Objects", позволяет хранить большие объемы текста. Используется для хранения изображений, звука, электронных документов и т.д.
"Тип данных" NULL
Вообще-то это лишь условно можно назвать типом данных. По сути это скорее указатель возможности отсутствия значения. Например, когда вы регистрируетесь на каком-либо сайте, вам предлагается заполнить форму, в которой присутствуют, как обязательные, так и необязательные поля. Понятно, что регистрация пользователя невозможна без указания логина и пароля, а вот дату рождения и пол пользователь может указать по желанию. Для того, чтобы хранить такую информацию в БД и используют два значения:
NOT NULL (значение не может отсутствовать) для полей логин и пароль,
NULL (значение может отсутствовать) для полей дата рождения и пол.
По умолчанию всем столбцам присваивается тип NOT NULL, поэтому его можно явно не указывать.
| ПОКАЗАТЬ количество записей в таблице, не вытаскивая сами записи |
SELECT COUNT(*) FROM [table name] |
| ВЫБРАТЬ указанные столбцы и их значения из таблицы |
SELECT [columns list, comma separated, or just * symbol] FROM [table name] |
|
выбрать указанную столбец и её значения из таблицы, БЕЗ ДУБЛИКАТОВ значений |
SELECT DISTINCT [column name] FROM [table name] |
|
выбрать указанные столбцы и их значения из таблицы, ЛИМИТируя количество выбираемых строк (работает в MySQL, PostgreSQL) |
SELECT [columns list] FROM [table name] LIMIT [number of records] |
|
выбрать указанные столбцы и их значения из таблицы, ЛИМИТируя количество выбираемых строк, начиная с определённой строки (работает в MySQL, PostgreSQL) |
SELECT [columns list] FROM [table name] LIMIT [number of record to start from],[number of records] |
|
выбрать указанные столбцы и их значения из таблицы, ЛИМИТируя количество выбираемых строк (работает в MSSQL) |
SELECT TOP [number of records] [columns list] FROM [table name] |
|
выбрать указанные столбцы и их значения из таблицы, УПОРЯДОЧИВ записи по возрастанию/убыванию одного из значений desc — descending, по убыванию asc — ascending, по возрастанию |
SELECT [columns list] FROM [table name] ORDER BY [column name] [asc/desc] |
|
выбрать указанные столбцы и их значения из таблицы, УПОРЯДОЧИВ записи по возрастанию значений двух колонок |
SELECT [columns list] FROM [table name] ORDER BY [column 1], [column 2] |
|
выбрать из указанных колонок таблицы те значения, ГДЕ соблюдаются определённые условия |
SELECT [columns list] FROM [table name] WHERE [condition] Примеры [condition]: WHERE somevalue BETWEEN 3 AND 50
WHERE t.ITEMID = 'FC0LUY-K48B/0000'
WHERE default_code [IN/NOT IN] ('FC00PE-FG6C','PCDKW2291C')
WHERE ringsize SIMILAR TO '%.[0-9]{2}'
WHERE default_code='FC00PE-FG6C' OR default_code='PCDKW2291C'
|
|
СЦЕПИТЬ значения из указанных колонок таблицы, "разделив" их указанным разделителем |
SELECT CONCAT(Capital, ', ' , Country) FROM customers |
|
СЦЕПИТЬ значения из указанных колонок таблицы, "разделив" их указанным разделителем, дав новое название этой общей колонке |
SELECT CONCAT(Capital, ', ' , Country) FROM customers AS [new column name] |
|
Выполнить АРИФМЕТИЧЕСКУЮ ОПЕРАЦИЮ для значений столбца, дав новое название этой колонке. Возможные операции +-*/ |
SELECT ID, FirstName, LastName, Salary+500 AS Salary FROM employees |
| Применить ФУНКЦИЮ для значений столбца |
SELECT FirstName, [UPPER/LOWER](LastName) AS LastName
FROM employees SELECT Salary, SQRT(Salary) FROM employees
SELECT AVG(Salary) FROM employees
SELECT MIN(Salary) FROM employees
SELECT SUM(Salary) FROM employees
|
|
Использование ПОДЗАПРОСА (выборка записей, где зарплаты выше средней) |
SELECT FirstName, Salary FROM employees WHERE Salary > (SELECT AVG(Salary) FROM employees) ORDER BY Salary DESC |
|
выборка ИЗ РАЗНЫХ ТАБЛИЦ (самый примитивный способ), указывая нужные столбцы (из разных таблиц) после SELECT и "соединяя" таблицы по условию после WHERE |
SELECT customers.ID, customers.Name, orders.Name, orders.Amount FROM customers, orders WHERE customers.ID=orders.Customer_ID ORDER BY customers.ID; |
|
INNER JOIN (эквивалентно JOIN) возвращает строки, в которых есть совпадения (по условию) между таблицами |
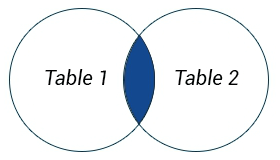 SELECT column_name(s)
SELECT column_name(s)FROM table1 INNER JOIN table2 ON table1.column_name=table2.column_name |
|
LEFT JOIN возвращает все строки из левой таблицы + совпадения по условию с правой таблицей там, где оно есть. Ключевое слово OUTER может быть опущено |
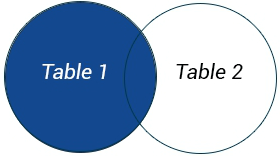 SELECT table1.column1, table2.column2
SELECT table1.column1, table2.column2FROM table1 LEFT OUTER JOIN table2 ON table1.column_name = table2.column_name; 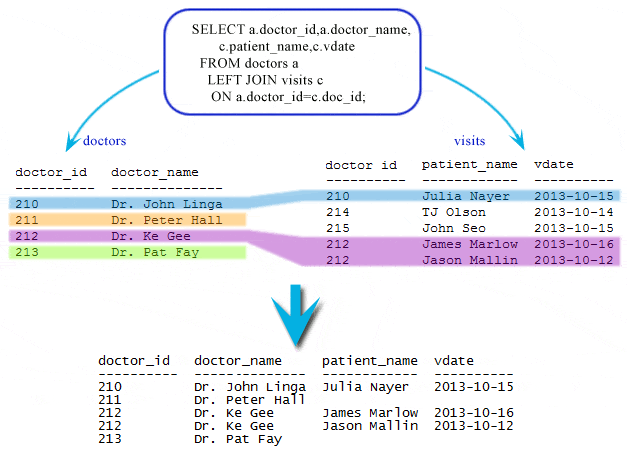 Источник изображения = https://w3resource.com/sqlite/sqlite-left-join.php
Источник изображения = https://w3resource.com/sqlite/sqlite-left-join.php
|
|
RIGHT JOIN возвращает все строки из правой таблицы + совпадения по полю с левой таблицей там, где они есть. Ключевое слово OUTER может быть опущено |
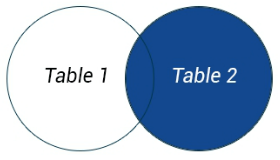 SELECT table1.column1, table2.column2
SELECT table1.column1, table2.column2FROM table1 RIGHT OUTER JOIN table2 ON table1.column_name = table2.column_name; |
| CROSS JOIN, т.н. декартово произведение, сиречь комбинация каждой строки "левой" таблицы с каждой строкой "правой" таблицы. |
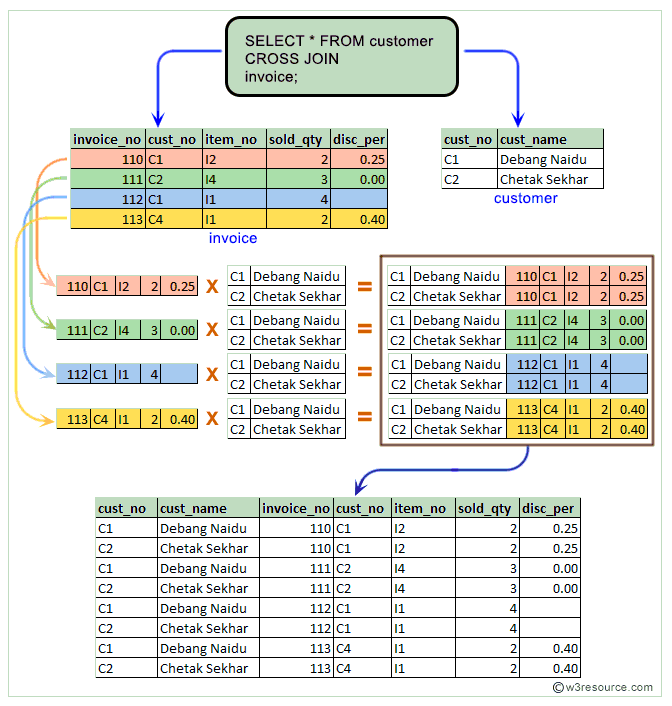 Источник изображения = https://w3resource.com/PostgreSQL/postgresql-cross-join.php
Источник изображения = https://w3resource.com/PostgreSQL/postgresql-cross-join.php
|
|
ОБЪЕДИНЕНИЕ данных из выборок Обе выборки должны иметь одинаковое количество столбцов, содержащих данные одинакового типа, столбцы должны идти в одинаковом порядке. В выборке-результате будут отсутствовать полностью идентичные строки. |
SELECT column_name(s) FROM table1 UNION SELECT column_name(s) FROM table2; |
|
Совет: ОБЪЕДИНЕНИЕ ВСЕХ данных из выборок для случая, когда мы хотим видеть так же и попадающиеся идентичные строки |
SELECT column_name(s) FROM table1 UNION ALL SELECT column_name(s) FROM table2; |
|
Совет: ОБЪЕДИНЕНИЕ данных из выборок для случая, когда мы точно знаем, что в таблице1 есть столбец, которого нет в таблице2, мы можем использовать NULL |
SELECT FirstName, LastName,Company FROM businessContacts UNION SELECT FirstName, LastName, NULL FROM otherContacts; |
|
ВСТАВКА добавляет новую строку с данными в таблицу. Убедитесь, что порядок вставляемых значений соответствует порядку соответствующих им колонок в таблице. Имейте в виду, что при ВСТАВКЕ вы обязаны указать значения для колонок, не имеющих значений по-умолчанию или не поддерживающих NULL. |
INSERT INTO table_name VALUES (value1, value2, value3,...); |
| ВСТАВКА новой строки с данными в таблицу по столбцам в указанном вами порядке |
INSERT INTO table_name (column1, column2, column3, ...,columnN) VALUES (value1, value2, value3,...valueN); |
|
ВСТАВКА новой строки с данными в таблицу только в указанные столбцы. Имейте в виду, что при ВСТАВКЕ вы обязаны указать значения для колонок, не имеющих значений по-умолчанию или не поддерживающих NULL. |
INSERT INTO Employees (ID, FirstName, LastName) VALUES (9, 'Samuel', 'Clark'); |
| ОБНОВЛЕНИЕ данных в таблице в строках, подпадающих под указанные условия |
UPDATE table_name SET column1=value1, column2=value2, ... WHERE condition; UPDATE sale_order
SET flash = true WHERE id = 99569 AND text LIKE "%some text%" |
| УДАЛЕНИЕ строк из таблицы по указанному условию |
DELETE FROM table_name WHERE condition; |
| ДОБАВИТЬ столбец в таблицу | ALTER TABLE [table name] ADD [column name] [data type]; |
| УДАЛИТЬ столбец из таблицы | ALTER TABLE [table name] DROP COLUMN [column name]; |
| УДАЛИТЬ таблицу | DROP TABLE [table name] |
| ИЗМЕНИТЬ столбец в таблице |
ALTER TABLE [table name] CHANGE [firstname] [newname] [datatype] |
| ПЕРЕИМЕНОВАТЬ таблицу | RENAME TABLE [firstname] TO [newname] |
Консольное выполнение запросов с записью результатов в файл:
создаём файл SQL-скрипта, например input.txt:
use databasename;
select * from dbo.tablename where something = '369767'
go
Выполняем в консоли по шаблону:
sqlcmd -S 1.1.1.1 -i [путь до скрипта] -o [путь до файла с результатом]
Например:
sqlcmd -S 1.1.1.1 -i "request.sql" -o "response.csv" -h-1 -s";" -W
Синтаксис тут: https://learn.microsoft.com/ru-ru/previous-versions/sql/sql-server-2008-r2/ms162773(v=sql.105)?redirectedfrom=MSDN
Или тут: https://learn.microsoft.com/ru-ru/sql/tools/sqlcmd-utility?redirectedfrom=MSDN&view=sql-server-ver16
Удалённое выполнение джобов: sqlcmd -S 1.1.1.1 -Q "MSDB.dbo.sp_start_job @job_name='jobname', @step_name=N'stepname'"
поиск дубликатов записей
select something, count (*)
from table
group by something
having count(*)>1
работа с датами
and CreatedOn > CAST(GETDATE()-10 AS DATE) and CreatedOn > CAST('2016-12-11' as DATE) and CreatedOn > '2016-13-12 05:20:00.000' and TimeStamp between CAST('2017-02-20' as DATETIME) and CAST('2017-02-21' as DATETIME) and CreatedOn > DATEADD(month,-3,GETDATE())
Получить названия колонок какой-либо таблицы
select * from DBNAME.Information_schema.columns where TABLE_NAME = 'mcs_StopFactorCheckResult'
PATINDEX
Получить первые 40 символов из колонки column2 (назвав её rezult), если значение в колонке соответствует заданному шаблону: SELECT Column1, substring(Column2, 1,40) as rezult FROM table WHERE PATINDEX('123%', Column2) > 0
Вернуть часть строки, начинающуюся с выражения (в данном примере — начинающуюся с HOST): select substring(column, PATINDEX('%HOST%',column),len(column)) as somesubstring FROM dbase.table
Как задаётся шаблон для LIKE